
几周前,Jeff 花了两天将自己的WordPress 网站做了个微信小程序版本(详细见该文)。这篇文章主要记录自己在开发第一版的过程,顺便为有兴趣的你剖析如何将一个WordPress 网站借助 REST API 开发微信小程序版。本文目标受众为了解WordPress 且有初级前端知识的同学。
原理篇
WordPress 与 REST API
WordPress 在4.4 版本后推出了 REST API, REST API 简单来说就是一种通过 HTTP 请求来获取、更新、删除数据的一种连接客户端与服务端的交互方式。我们访问平常的普通 WordPress 网页,在没有开启静态缓存的情况下,大概是走“从数据库拉取数据—> 服务端 PHP 进程拼成 HTML 直接输出 —> 用户浏览器界面”的过程, REST API 也是类似步骤,但后面两步稍微不同:输出的是 JSON 格式的数据且一般是给客户端使用。有了REST API,一个网站制作各种网站版本(安卓版、iOS 版、以及接下来说的小程序版)而共享一个数据库成为了可能。
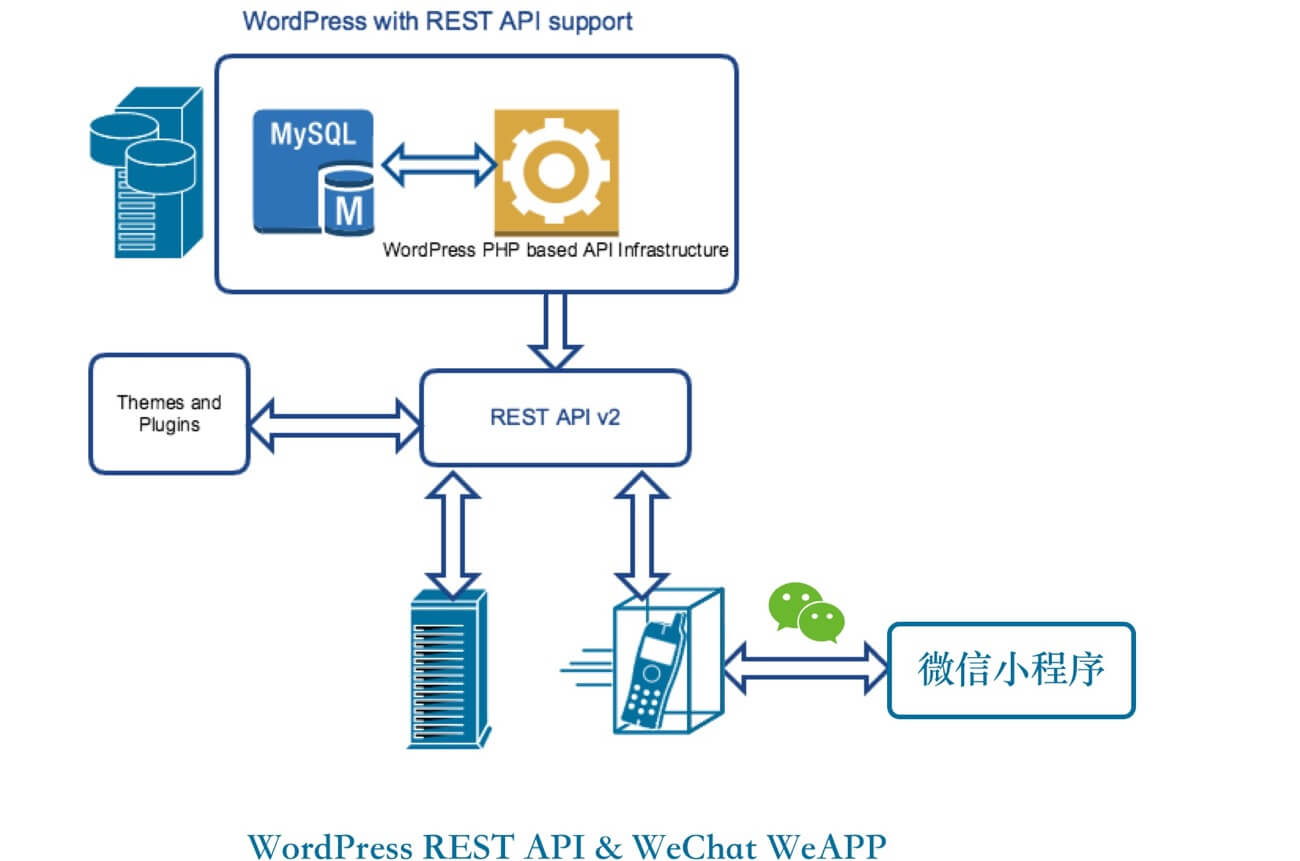
(原图来自wisdmlabs,稍作修改)
以本站为例,可通过浏览器直接访问REST API 的其中一种URL:https://devework.com/wp-json/wp/v2/posts?per_page=5&page=1 (如果你现在直接访问是403 报错,那是我为了安全而设置的拦截,请自行替换为自己网站的域名),你可能会看到如下图左侧的界面;如果你使用Chrome 浏览器且安装JSONView 插件则为下图右侧的界面。
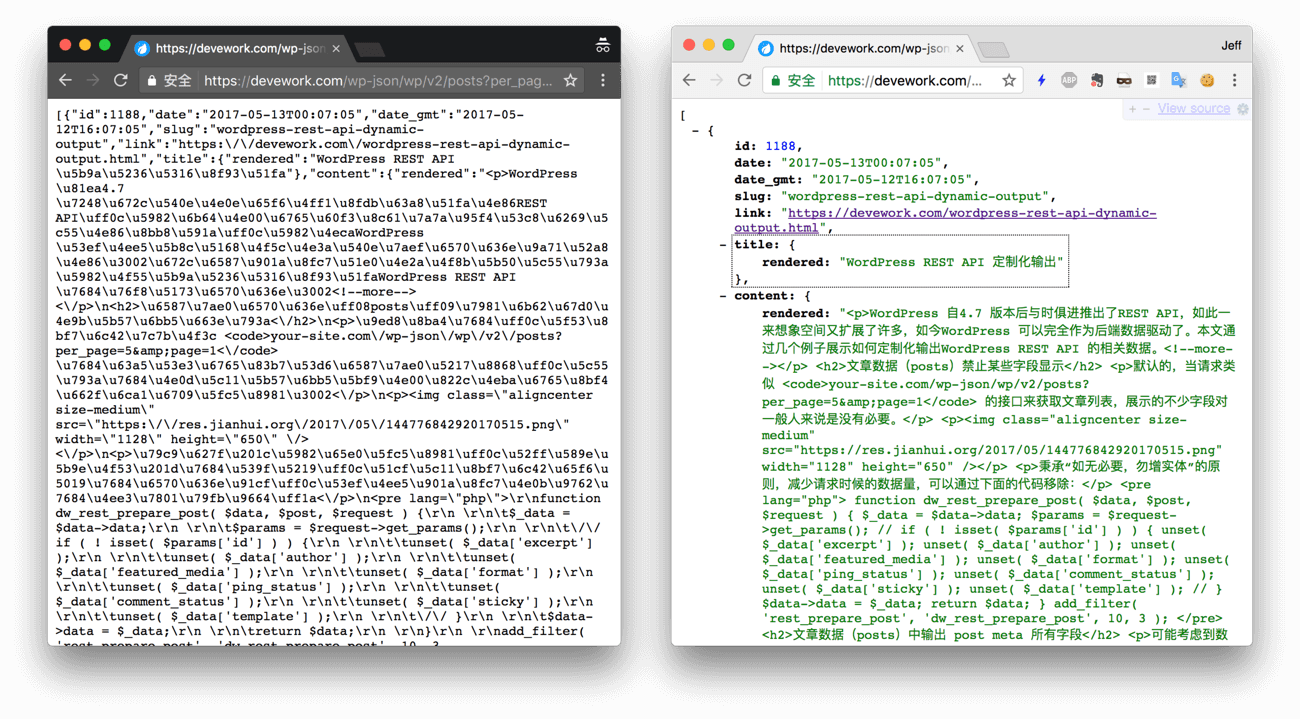
且让Jeff 将上面的URL 解释下,/wp-json/wp/v2/ 这个是WordPress 定义的REST API 的“路由”(router)与版本号等的组合,合在一起称作“命名空间”(namespace),posts 在WordPress中称为“终点” (endpoint),per_page 与page 则是相关参数。 关于REST API 的名词解释可以参考阮老师的文章。上面的URL 即表示输出第1页最新5篇文章的数据(5篇为1页)。这个URL 接下来将要用到。
微信小程序
微信小程序就不多介绍了,虽然刚开始不温不火,但接下来必然是在国内互联网占据一定的地位。本文在这里也不多谈什么小程序前景如何这些空大话,既然你看到这儿必然是对小程序有兴趣且在某种程度上有一定的肯定。
WordPress + 小程序
微信小程序通过 REST API 获取到 WordPress 网站上的数据,然后通过一定的方式在小程序端进行数据处理后通过前端代码渲染,然后就是你在微信客户端上看到的界面。
WordPress 的REST API 现在开发得已经很完善了,什么文章数据、页面数据、用户数据等都不在话下,把 WordPress 作为小程序的后端实在是省了不少人力,至少对我们这些前端狗来说不用写苦逼的后端代码。
开发篇
上一章节大致介绍了原理后,接下来就以本站开发的“DeveWork极客”小程序第一版v1.0 为例,介绍三个页面(首页、内容页、阅读记录页)大体上是如何做出来的。可以扫描下面的小程序码体验一下,注意看文章的此时你扫描进入的版本可能不是不是第一版了。要看懂本章节的内容,需要你对小程序开发有一定的了解(不要求看完文档,但至少也跑一下官方的例子吧)。另外本章节也不会涉及如何写CSS(WXSS)的部分,默认读者有这方面的基础。

准备工作
准备工作就不细说,大体上包括如下操作:一是微信公众平台管理后台上注册小程序账号,配置域名等信息;二是服务端确保配置好HTTPS、“合法域名”这块是已经备案的域名。
另外在开始开发之前,我在服务端对WordPress REST API 进行了一些定制化的输出。
项目结构
结合微信官方quick start 的例子与个人需求,将项目结构如下分好:
. ├── app.js ├── app.json ├── app.wxss ├── config.js // 配置文件 ├── image // 图片目录 ├── pages // 页面目录 ├── utils // 实用untils 类 └── wxParse // 第三方库wxParse |
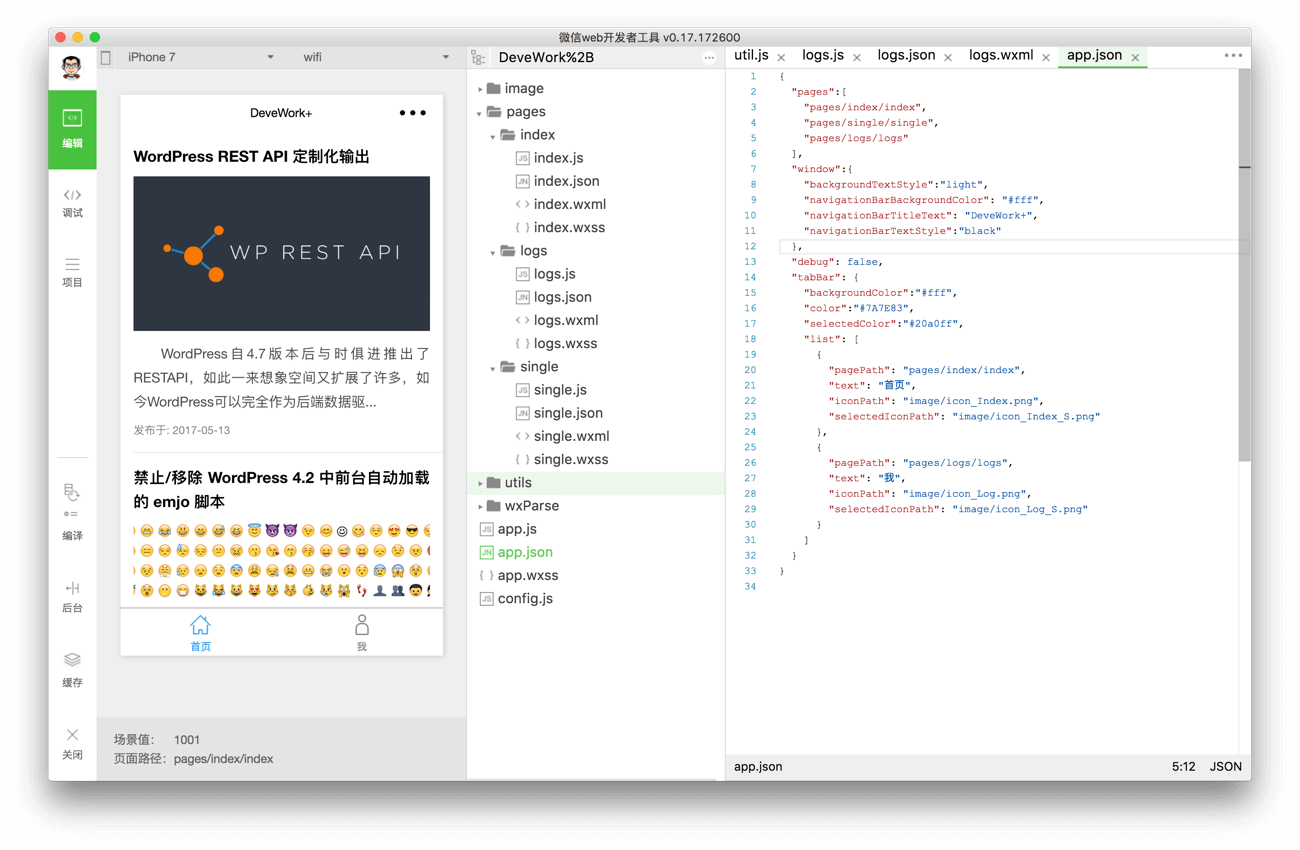
小程序首页(文章列表页面)
首页即文章列表页面, 即展示最新的5篇文章,然后通过下拉流式加载更多文章(有点无限加载的意味)。使用到WordPress 的REST API 就是 your-site.com/wp-json/wp/v2/posts?per_page={num}&page={num}。
index.js 文件里面核心是通过wx.request 接口访问上面的API URL 获取到文章数据并setData 供后续数据渲染:
// https://devework.com/wordpress-rest-api-weixin-weapp.html wx.request({ url: url, success: function (response) { self.setData({ posts: self.data.posts.concat(response.data.map(function (item) { ... // 数据过滤/格式化等 ... return item; })) }); } }); } |
上面的代码我是抽出在一个函数中,方便后续重复调用。设置的数据通过index.wxml 循环输出,当前在此之前因为要做滚动加载,所以采用了小程序的scroll-view组件(官方文档)。
<scroll-view scroll-y="true" bindscrolltolower="pullDownRefresh">
<block wx:for-items="{{posts}}" wx:key="{{item.id}}">
<view class="entry" index="{{index}}" id="{{item.id}}" catchtap="redictSingle">
<!--文章数据的展示,细节代码略过-->
</view>
</block>
</scroll-view> |
上面的WXML 代码中绑定了两个事件函数:一是下拉事件pullDownRefresh(),一个是点击事件redictSingle(),即点击后跳转到文章详情页。
// https://devework.com/wordpress-rest-api-weixin-weapp.html // 下拉刷新 pullDownRefresh: function (event) { var self = this; self.setData({ page: self.data.page + 1 //页面+1 }); console.log('current page:' + self.data.page); this.fetchData({ page: self.data.page }); }, // 路由导航到文章内页 redictSingle: function (event) { console.log('redictSingle'); var id = event.currentTarget.id; // 这里的id 其实是WordPress 中的文章id,需要传递到single 页面 var url = '../single/single?id=' + id; wx.navigateTo({ url: url }) } |
文章内页(文章详情页面)
文章页使用到的REST API URL是your-site.com/wp-json/wp/v2/posts/{id}。也是类似,通过wx.request 接口访问URL 然后渲染数据到WXML 页面上。代码与上面的类似就不重复了。
这里其实涉及到个如何将富文本转为微信小程序可识别的WXML 的问题。因为获取的JSON 数据文章正文部分是一段HTML 代码,如果直接输出是会报错的,需要将这段HTML 代码(俗称富文本)转化为微信小程序WXML 语言。Jeff 使用的是WxParse 这个第三方库,不过这个库目前来说依然不是很完善,接上去之后发现有不少 bug,还好凭借自己的技术给打补丁般一个个修复了。
使用上,按照WxParse 的文档,在获取到文章数据后,经过html to wxml 的步骤后赋值到page data:
// https://devework.com/wordpress-rest-api-weixin-weapp.html // html to wxml let article = res.data.content.rendered; WxParse.wxParse('article', 'html', article, self, 5); self.setData({ wxParseData: article.nodes }); |
wxml 上,import 导入wxParse.wxml 并调用:
// https://devework.com/wordpress-rest-api-weixin-weapp.html
// html to wxml
<import src="../../wxParse/wxParse.wxml"/>
<view class="entry__cotent ">
<template is="wxParse" data="{{wxParseData:article.nodes}}"/>
</view> |
以上就是接入WxParse 的过程粗略介绍。
7月29日更新:小程序现在出了富文本组件(rech-text),个人评价么,暂时还比不上 wxParse。当前支持的标签有限(如pre标签不支持)且不支持绑定事件,暂时还是先用着wxParse。
阅读记录页面
阅读记录页面是用来展示用户浏览历史,直接照着官方的Hello World 例子就做起来了。这个页面用到的主要如下两种接口:LocalStorage 相关接口、用户授权相关接口(wx.login,wx.getUserInfo等)。
从用户体验上考虑,不应该一开始就向用户申请授权,而是有需要的页面才申请;同时也应该做好用户不允许授权的优雅处理。在这里因为小程序的坑以及个人关系第一版处理得不是很完美,代码就不展示了。
6月14日更新:处理授权相关的内容参考本文《提升用户体验,微信小程序“授权失败”场景的优雅处理》
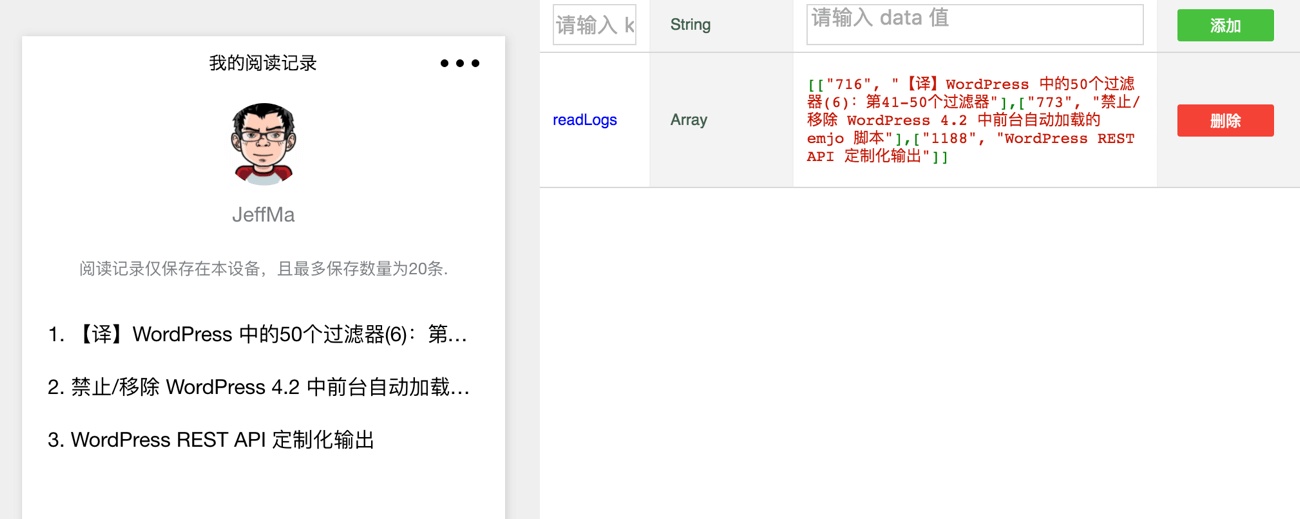
记录的文章阅读历史数据是以LocalStorage 的形式保存在客户端而非云端,一句“阅读记录仅保存在本设备”的提示是有必要的。同时基于容量上的考虑将最多数目限制为20条。
// https://devework.com/wordpress-rest-api-weixin-weapp.html // 调用API从本地缓存中获取阅读记录并记录 var logs = wx.getStorageSync('readLogs') || []; // 过滤重复值 if (logs.length > 0) { logs = logs.filter(function (log) { return log[0] !== id; }); } // 如果超过指定数量 if (logs.length > 19) { logs.pop();//去除最后一个 } logs.unshift([id, response.data.title.rendered]); wx.setStorageSync('readLogs', logs); |
上面的代码其实是放在single.js里面的,因为需要将文章id 与标题保存在LocalStorage 上,只有single.js才同时获取这两种数据。
最后还需要在log.js 的onShow生命周期绑定一个更新数据的函数:
// https://devework.com/wordpress-rest-api-weixin-weapp.html updateData: function(cb){ var that = this; // readlog this.setData({ readLogs: (wx.getStorageSync('readLogs') || []).map(function (log) { return log; }) }) }, |
踩坑篇
这个章节主要记录在开发过程中的一些坑以及解决方案。
TabBar 的图片问题
小程序官方宣称支持SVG 图片,但在tabBar 里面的图片并不支持SVG 图片。官方推荐采用81x81 尺寸的png 图片,但这个依然有点坑。建议在设计icon 的时候稍微留点透明的padding 占位,不然会导致图标在真机上会放得很大。
图片防盗链的referer 设置
如果你托管图片的服务器有防盗链处理,那么得将servicewechat.com放入白名单中,并不是想当然的qq.com。
Image 的绝对路径必须以https 开头
image 的src 绝对路径,在web 开发中是允许类似//example.com/pic.png的以//开头的存在,这种图片路径在微信web 开发者工具也能正常显示,但在真机上就不能正常加载了,必须是https 开头的绝对路径。
服务端数据侧不好处理的话可以通过下面的util 处理:
// https://devework.com/wordpress-rest-api-weixin-weapp.html // 补全URL 中缺失的 HTTPS function addhttps(url) { if (!/^(f|ht)tps?:\/\//i.test(url)) { url = "https:" + url; } return url; } |
开发者工具的小程序UA 与实际UA 不同
开发工具中模拟的小程序UA 是类似:
... Chrome/53.0.2785.143 Safari/537.36 appservice webview/100000 |
而通过Nginx 的log 可以查看到实际的UA 是类似(其实就是微信的UA):
... Mobile/14E304 MicroMessenger/6.6.0 NetType/WIFI Language/zh_CN |
某些情况下需要注意这些不同。
默认的Flex 布局
如果你是在官方例子的代码基础上开发你的小程序的,建议先删掉app.wxss 的flex 布局相关代码,会降低你遇到奇葩样式问题的概率。
wxParse 的坑1:code 字符被错误替换
小程序使用到的富文本转化是用wxParse 这个第三方库,用的时候发现有不少坑(但目前是这个库最为实用了)。其中一个就是全局的code 字符都被替换为wx-codexxx 类似的坑,作者本意应该是对code 标签进行这个替换,但可能一不小心写错了。解决方案是暂时删掉那段代码。
wxParse 的坑2:image的src 多解析出一个逗号
看图说话:
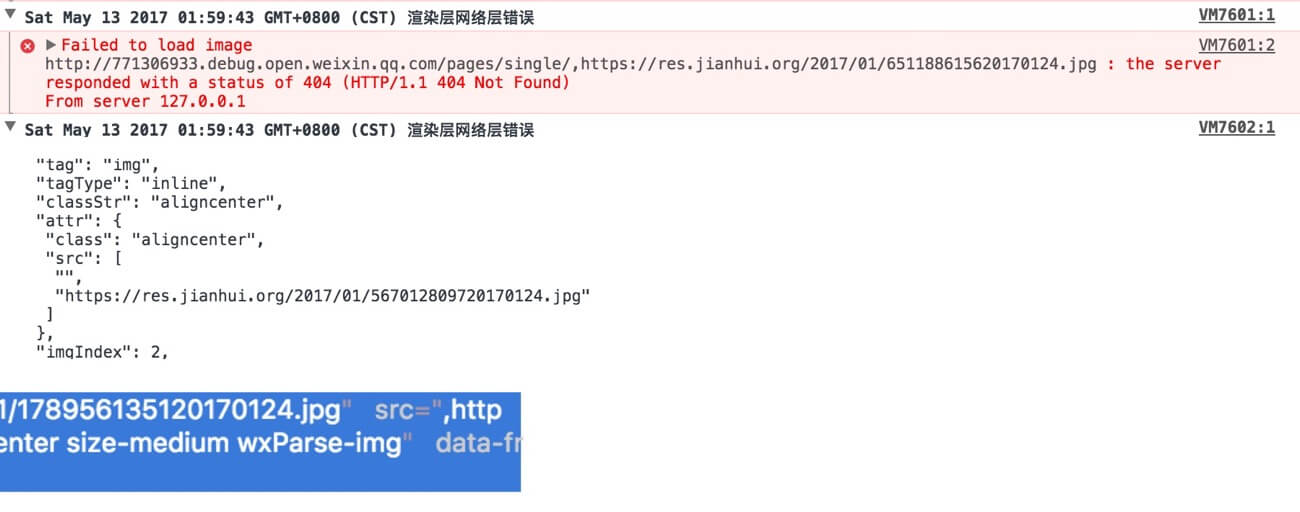
上图也很好解释了上面的referer 坑与图片路径https 开头的坑。解决方案只能先改动源码(html2json.js 约L130)Fix 下:
// https://devework.com/wordpress-rest-api-weixin-weapp.html // Fix: img 标签数组含有空字符的问题 if (imgUrl[0] == ''){ imgUrl.splice(0, 1); } |
总结篇
至此详略得当地介绍了开发这个WordPress 版小程序的过程,接下来的工作自然是提交到官方并耐心等待审核结果的通知。整个开发过程其实并不太有难度,如果之前有使用过Angular、Vue 这类MVVM 框架,整个开发过程基本上只是看官方文档的问题。
希望本文对你有帮助,本站后续也会有一系列关于小程序开发的文章,欢迎关注。
附:本系列文章:
附:本文更新历史记录
8月16日更新:根据小程序最近的开放接口相应更新部分过时内容。
7月8日更新:被人告知我的这篇文章的某些内容被人以某种形式“抄袭”了去,在此声明:本文为原创文章,如果看官有幸看到那篇“抄袭”的文章,请不要认为我这篇是抄袭人家的哦~
附:本站“微信小程序”系列文章:https://devework.com/tag/weapp
学习了!如果开源了更好!
能否把全部代码贡献学习一下啊。
好干货
哇哦,好厉害:smile: 我也来做一个
在文章列表页用wxParse怎么循环过滤html?循环模板里面不知道该怎么用(后台是wordpress)





你可以去找段去除 html 代码的 js 脚本;或者可以直接在服务端进行过滤,即定制 rest api 的输出结果。
你用的什么方法?可以分享下么
想转载至自己的博客上,会保留版权并标明出处和网址,希望作者能授权
你好,可以的
在保留署名的情况下欢迎自由转载
必须保留。。。
感谢踩坑,图片防掉链问题想了半天也没想到是那个域名,23333
你好!我们是爱范儿旗下专注于小程序生态的公众号知晓程序(微信号 zxcx0101)。我们很赞赏你的文章,希望能获得转载授权。授权后,你的文章将会在知晓程序社区(minapp.com)、爱范儿、AppSo 等渠道发布。此外,由于第三方同步抓取功能,您的内容也可能会被同步发表到今日头条、搜狐、网易号等,我们会注明来源和作者姓名。
你好,非常欢迎知晓程序转载
我的wordpress访问rest api出现404是什么情况,需要怎么配置吗?,wordpress版本是4.9
可能你的 Nginx 配置有问题
我从REST API中取到的概要介绍,前后都有标签,这个怎么处理?还有就是 REST API用POST的方式取回来的时候,分类category和tag都是数字ID而不是文字内容,这个有写转译的代码么?谢谢~
你说的两个问题应该都是在客户端处理的:1.将 html 代码转为纯文本,即过滤 html 标签 2. int to string
的问题。这两个问题你去搜索引擎搜索下就很容易解决的哈~
大神,开发这个小程序必须要配置ssl吗?帮开发一个怎么收费?
具体可以联系我本人哈(qq 麻烦注明来源)
请问缩略图应该如何调用啊
请见上一篇文章《WordPress REST API 定制化输出》
最近在折腾小程序,过来学习下。期待下一篇文章。如果后期有可能的话,在github上共享下代码呗 。
。
不好意思暂不开源
恩。没事。有分析开发过程的文章也挺好了。
什么时候开源一下呗,我们可以赞赏或者付费。
不好意思暂时不开源
现在能开源吗?或者有基础代码可以学习下吗??小白一个,有些看不懂。
请问下,那个在浏览器一键排版的用的是什么插件
你好,请仔细看文章哦